Supervision Required: Why all the data in the world may not be enough
Supervision Required: Why all the data in the world may not be enough
By Gary Angel
|February 12, 2019
We use a variety of sensors to track shopper movement in stores. And to do that more accurately, we re-engineered our processes to take advantage of machine learning. You can get the full skinny on the basics of geometric positioning and why ML might work better in this post. But once we decided to go in that direction we ran into a HUGE problem. Because even though we had terabytes of data, we didn’t have the right kind of bytes to do machine learning.
Our electronic data comes from an array of sensors positioned in the store. When a shopper’s device (smartphone) probes for a network, these sensors detect the signal and measure the signal strength. The data we get from each sensor looks like this:

We combine all the signals from a single probe to see the different sensors it was detected on and their respective signal strengths. Here’s a sample for a single probe:

Since we know the position of each sensor in the store, we can trilaterate this data to establish a hypothetical position for the emitting device. But suppose we want to use ML to do the same thing? We have millions of these rows – so there’s plenty of data to learn from.
But there’s nothing to learn!
ML techniques almost always rely on having a defined outcome in the data that allows the algorithm to test whether a prediction is good or bad. But for all of these records, that position is what we’re trying to figure out. We have – literally – millions of questions but not one single answer.
That doesn’t work when it comes to ML.
What we need is a set of the same kind of data along with the true position of the emitting device. Then – and only then – can we do supervised machine learning. And supervised ML is what you pretty much always want to do.
Since we didn’t have this data, we decided to make it. And the process of making ML ready data was an epic unto itself. A lot of folks do fingerprinting by carrying a phone, standing in a spot, and cycling the Wifi network to generate a probe.
If you walk to 10-15 spots you have a sample of how the sensors will pick up signals across the store.
Those fingerprints may be good enough to, for example, mathematically tune a trilateration. But having a few probes from the phone for a spot isn’t remotely enough data to do machine learning.
To make matters worse, smart-phones these days generally don’t let you cycle WiFi requests more than about every 15 seconds. So if we wanted to generate something like 1000 samples for a location, we’d have to cycle the phone for about four hours in a single spot. Ouch. That’s like serious carpal tunnel time.
So step 1 for us was to create modified devices that would ping pretty much constantly. We found we could usefully ping about every second on a device. That’s a 15-fold reduction in the amount of time we need to spend per location to generate enough signals to use ML to generate a fingerprint.
But why limit yourself to one device? For calibrations we arm the calibrator with an array of devices and position them in various places. This not only gets us more data, but helps us correct the signals for the different orientation of phone/body/sensor. After all, if we know where the tester is we know where all the devices are. So step 2 is to use multiple phones all blasting simultaneously.
For this to work, though, we still need the true position of the tester. When we started this, we marked positions on a map and had the calibrator record the time that they were at each position. It worked, but it kind of sucked too. First, like any manual component in a process it created inevitable errors and confusion. Mis-timings and missed timings were legion and problematic.
We also found that spot calibration yielded very inconsistent results. There’s too much chance of relatively small shifts in position causing significant changes in line-of-sight blockages and received signal strengths. What we developed was a combination of plan and tracker that allowed us to record each probe the phone generated, the area it was generated from, and the X,Y coordinates.
These are saved in (pretty massive) local files on the calibration main phone and then transmitted to our servers when the calibration is finished.
It’s a complicated enough process that we created not only detailed instructions but a set of videos we have our calibrators view to both assemble the calibration kit and then execute the process. You can’t beat Youtube videos for that kind of instruction!
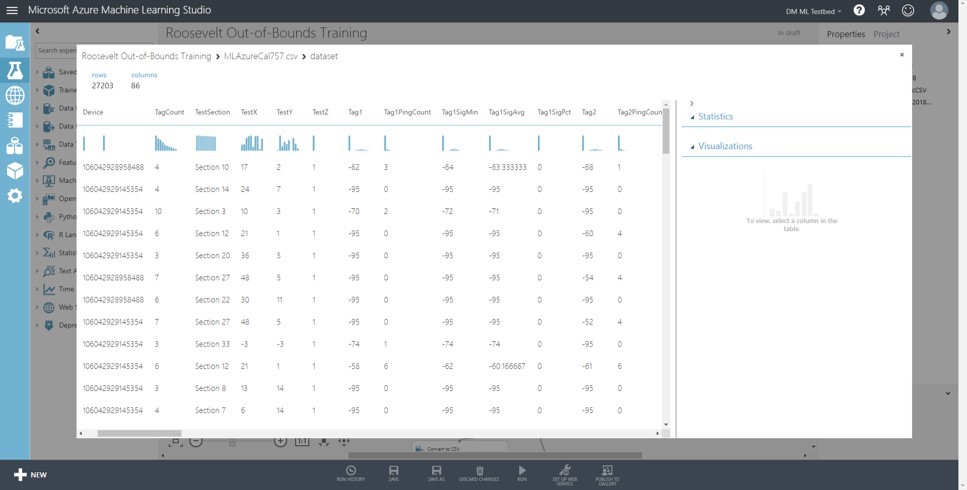
We join the calibration data from the mobile app to the collected data from the sensor feed based on device identity and timestamp:
Now we have a large set of observations that contain a device identifier, a timestamp, the signal strengths collected at every sensor for a probe AND the true X,Y coordinates of the phone as well as a code for the calibration area (a smallish bounding box usually on the order of 3×3 meters).
This, my friends, is an ML-ready data set.
Or is it?
In my next post I’ll look at some of the problems our slightly artificial calibration data caused us and the techniques we used to generate a better, more representative training data set.