ChatGPT and BI Integration: Getting SQL Generation Right
ChatGPT and BI Integration: Getting SQL Generation Right
By Gary Angel
|April 8, 2024
Like everyone managing a BI product, we spent a good chunk of last year working to integrate AI (and specifically ChatGPT) into our product. We worked on three levels: a SQL Generator to give people who need data they can’t get from the platform but aren’t SQL mavens, an Insights Generator to pair with reports and views in the platform, and a Q&A interface to potentially replace basic platform usage and shorten or direct analytic sessions.
We decided to tackle SQL Generation first. ChatGPT has very robust SQL generation and this seemed like the easiest way to start using the API. We already support a range of feeds and building an interface that allowed users to ask questions and generate SQL didn’t involve any deep UI integration or complexity. In retrospect, this still seems like a good decision. Building the basic interface was easy and it allowed us to quickly explore the use of the ChatGPT API. And since we’re a bunch of technical analysts and programmers, we were able to easily evaluate the quality of the output.
Here’s how it looks in the interface:
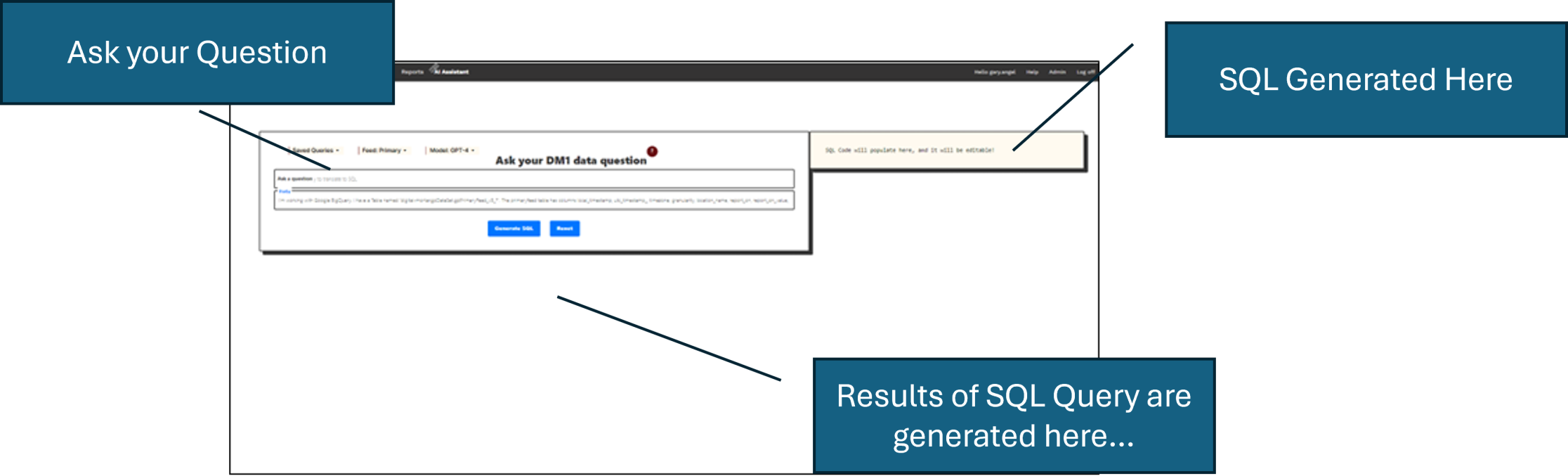
You enter your question and press the Generate SQL button. We pass your question to ChatGPT, get the corresponding SQL back and then run that SQL against the underlying database. Note the all-important context (the line beneath the question). We pre-load this with a little bit of context so that ChatGPT knows the name of the database, what tables and columns are available, and that the return should be SQL code.
Here’s our initial context:
I’m working with Google BigQuery. I have a Table named tablenamehere*. The table has these columns local_timestamp, utc_timestamp_, timezone, granularity, location_name, [etc.]
When the user enters a question, we get the ChatGPT SQL. Then we execute the SQL and return the data right into the interface. A non-analyst can get full access to the data without knowing any SQL.
Or can they?
Our base implementation of this didn’t work very well. If you were skilled in SQL, the ChatGPT interface could sometimes make writing a SQL query a little faster (and save you a trip or two to StackOverflow if, like me, you’re not constantly writing SQL). But if you weren’t a SQL-user the capability was worse than useless.
It was mostly useless since very few of the queries actually executed successfully. So test users got a lot of this:
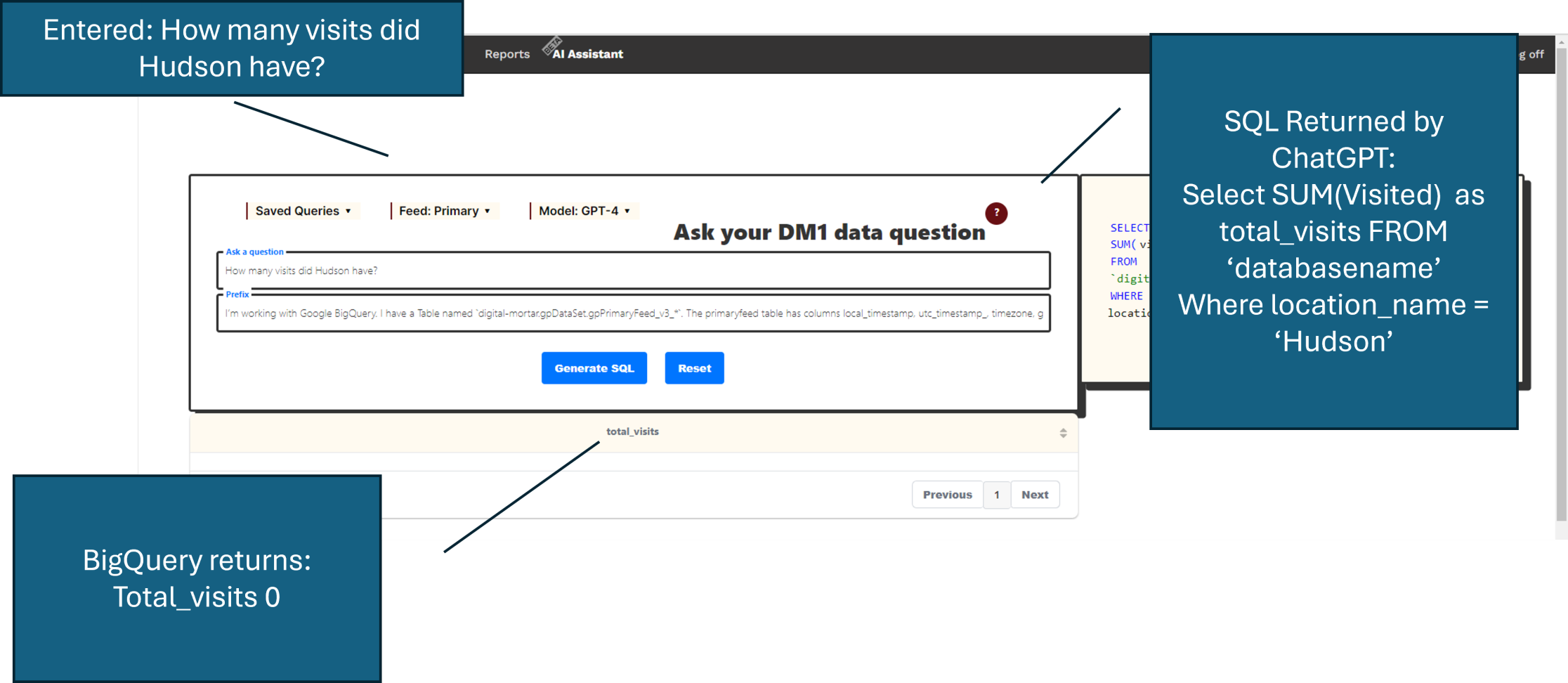
This query failed, but it highlight some of the brilliance of ChatGPT. ChatGPT correctly inferred that Hudson was a location_name without us telling it that. That’s damn impressive. Unfortunately, the formatted location name isn’t Hudson – so the query didn’t work and the returned value was 0.
In this question, I used the fully formatted location name. An end user might know this or they might not:
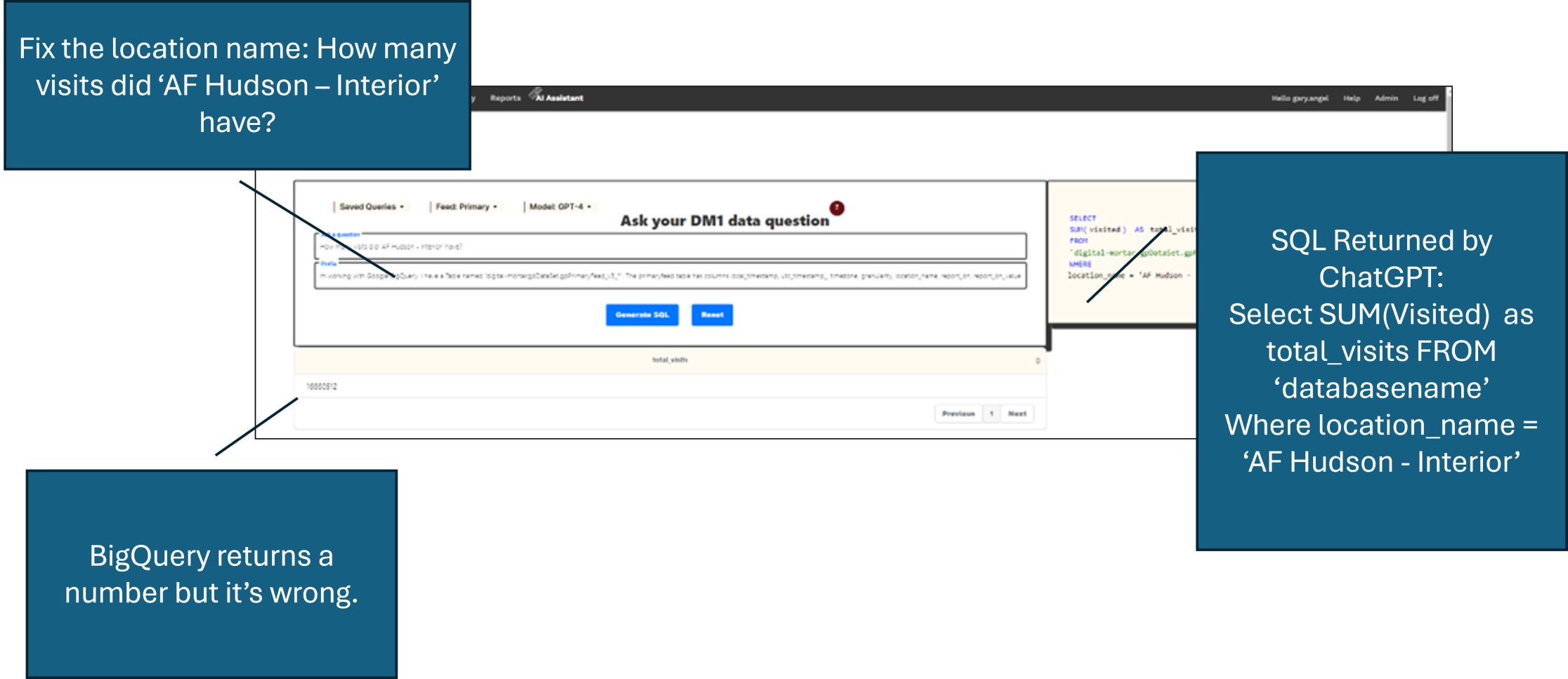
Unfortunately, that answer is very wrong and good luck figuring out why if you don’t know both SQL and a fair amount about the underlying data. So, our original ChatGPT SQL generator was useless when it didn’t produce executable SQL and worse than useless when it did since the answer was nearly always something different than the user wanted.
One thing we built right into the first iteration of the tool that proved extremely valuable was logging every query and result. These logs revealed a host of problems in the way ChatGPT was interpreting our tables and getting the resulting SQL wrong. We also appended a request for explanation to every query and stored that as well. This let us easily review what users were asking, what ChatGPT was returning, and what it thought it was doing.
What kind of mistakes did ChatGPT make?
It didn’t understand how location data worked. It didn’t understand that there were multiple levels of mapping for each location. It didn’t understand questions driven by specific values in key columns (like about store areas). It didn’t understand our metrics or how they related to potential English language questions or questions about success and performance. Finally, it tended to answer every question with a complete haul of all the data (which was disastrous from a performance perspective), and it tended to misinterpret questions about a specific month (like December).
None of this has anything to do with the capabilities of an LLM. LLM’s aren’t magic and they don’t work the way an analyst might. Ask an analyst a question and if they haven’t ever used a specific database before, they will likely explore the values and structure of that database before they give you an answer. You’d be right to think poorly of an analyst using a database for the first time who wrote a single query and then gave you the results. ChatGPT – especially when used via the API – isn’t an analyst.
For almost every database I’ve ever used, you have to know something about the underlying data structure before you can query it effectively. If you want to use ChatGPT against a database, you have to give it that knowledge.
And that’s exactly what we did using the context.
The context is prepended to the users question every time we make an API call. In effect, it becomes part of the dialog and knowledge ChatGPT has when building the SQL. We tackled each of the issues above (and quite a few others) by adding information to the context.
The biggest problem we saw with user queries is that effective queries – particularly in where clauses – often requires very specific knowledge of the way the data is formatted and what data is in which column. In our database, for example, location_name is a common and critical field. The location names (as is common in our data) are based on the city where the store is. So, for example, a location is called Hudson because it is in Hudson, New York.
One very common kind of question asks about a specific location – something like “How many visits did Hudson have?”.
ChatGPT may or may not know that Hudson relates to location_name. In our case it did, but if we had a last_name field in our data, I’m not sure which ChatGPT would pick. But suppose you tell it that Hudson is a value in the location-name field. Now ChatGPT will generate a where clause like this:
Sum visit_count from database_name where location_name = ‘Hudson’
Your resident SQL programmer will cheer, but while this SQL will execute, it will return 0 as an answer. If you know SQL, you could figure out why in a second. But if you don’t?
The problem is that the location_name values are stored with a prefix and with a postfix of ‘Interior’ or ‘Site’ depending on whether the data is for the inside of the store or the entire store including the outside area.
We tell ChatGPT about this and how to interpret it.
This table contains data for gas station / convenience stores. The store name is in the location_name field. Store names are formatted as ‘AF ‘ concatenated to the location of the store followed by a ‘-‘ and the word ‘Interior’ or ‘Site’. A sample location_name is ‘AF Hudson – Interior’. The key part of this name is Hudson. That’s the location of the store and also the name I will use to query it. ‘AF Hudson – Interior’ and ‘AF Hudson – Site’ are the same store. However, ‘AF Hudson – Site’ includes data for both the outside gas station and the Interior convenience store. ‘AF Hudson – Interior’ only includes data for the convenience store.
The locations in the data are…(list here)
Each location has an Interior and a site version.
If a question asks about cars, gas or pumps, then data for the location name with ‘- Site’ should be used. Otherwise, always use the location name with ‘- Interior’.
That this works is a tribute to just how awesome ChatGPT is. ChatGPT will seamlessly use this to generate the correct fully qualified where clause for most questions that just use the city name as a proxy for the location_name. This particular case is especially challenging because of the combination of Site and Interior locations. But for all clients we autogenerate a list of the location names and insert them into the context.
This context also helps make sure that ChatGPT understands that there is duplication for a single location in the data and provides some basic guidance about when to use each version. These are the kinds of quirks in a data set that often trip up new users of the data and they’ll get ChatGPT as well.
The next problem we tackled is general to almost every BI use case. Users often write queries based on their knowledge of what’s in a key field. We now insert lists of all the distinct alpha-numeric values into the context for every important field. For example, we use this strategy for store sections. Our clients dynamically map their location with Section being the default level. We always give ChatGPT’s context a list of all the section values specific to that client. So if a user asks about ‘Dry Goods’ or ‘Beer’ or ‘Tennis’, ChatGPT knows where to look.
Giving ChatGPT context information about distinct values for key dimensions and explaining what they are is the single most important tune you can give to a ChatGPT SQL interface. This alone turned our SQL engine from totally useless to somewhat useful.
We solved other ChatGPT problems in a similar fashion. One of the biggest initial issues was ChatGPT’s tendency to think every query should be run against the entire data history. That’s brutal and rarely correct. We keep years of behavioral data for each location. Users almost never want to use all of it. But when a user asks a question like “how many visits did Hudson have?”, ChatGPT will write SQL that answers that question across the entire database history.
We solved this problem by adding the following into the context:
If I don’t reference any time period in my question, the question applies to the current month.
This works for us since our data is almost entirely date and location driven. We also provide ChatGPT guidance for how to handle queries that don’t contain a location (look at all Interior or Site locations and GroupOn location_name).
Another common problem arises from ChatGPTs tendency toward literalism. If I ask a human analyst a question like “How many visits did Hudson have in December?” they will write a query like this:
Select sum(visit_count) from database_name where Location_Name = “AF – Hudson Interior’ AND EXTRACT(MONTH FROM local_timestamp) = 12 AND EXTRACT(YEAR FROM local_timestamp) = 2023;
But ChatGPT is more literal. You said December not the most recent December. So ChatGPT will give you something like this:
Select sum(visit_count) from database_name where Location_Name = “AF – Hudson Interior’ AND EXTRACT(MONTH FROM local_timestamp) = 12
Keep in mind that the return value is just a number. It won’t show a date range. Chances are that someone who doesn’t understand SQL won’t recognize that their December number includes data from 2022 and maybe 2021. Ouch.
So we give ChatGPT a little help:
When asking questions about time, if a question only contains a month name, use the most recent year for which that month has passed or is currently in when building the sql. If the current month is January and the question is about December, then use the previous year. But if the question is about March and the current month is April (or May or June, etc.) then use the current year.
So if I ask for Visits as Hudson in October and todays data is November 15, 2023, then the SQL where clause would be:
Where Location_name = ‘AF Hudson – Interior’ and report_on = ‘Location’ AND EXTRACT(MONTH FROM local_timestamp) = 10 AND EXTRACT(YEAR FROM local_timestamp) = 2023;
This kind of context helps a lot but we still see times when ChatGPT gets it wrong. One other takeaway I’ll call out here is that we found that providing samples was often critical to getting ChatGPT to get the lesson right. ChatGPT can handle a fair amount of verbiage – it did very well with the text we gave it to properly format location names, for example. But you’ll be surprised how often it will get things like this wrong unless you give it – in training or context – an actual example(s).
We include examples of SQL for almost every single thing we tune in the context.
When we first started down this approach of building out context, there were some fairly sharp limitations on how much context we could provide (usually only 4096 characters). You’d be surprised how fast you chew that up. But in OpenAI’s unending round of improvements, the context in ChatGPT grew dramatically in size. We typically send anywhere from 20k-40K of context with every SQL request. The improvement in result quality is dramatic.
Now, when users ask ChatGPT common questions, they get SQL that runs and it usually is giving them the data they wanted:
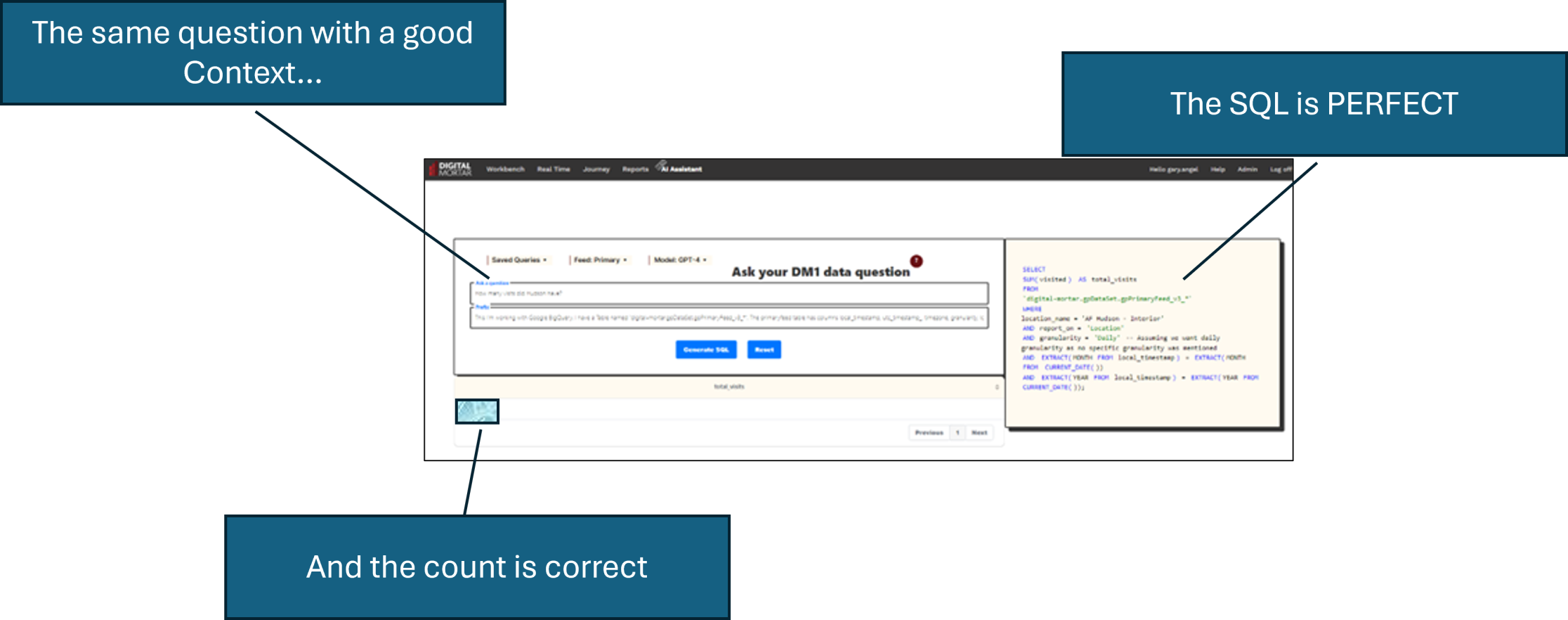
Even significantly more complicated queries get handled perfectly:
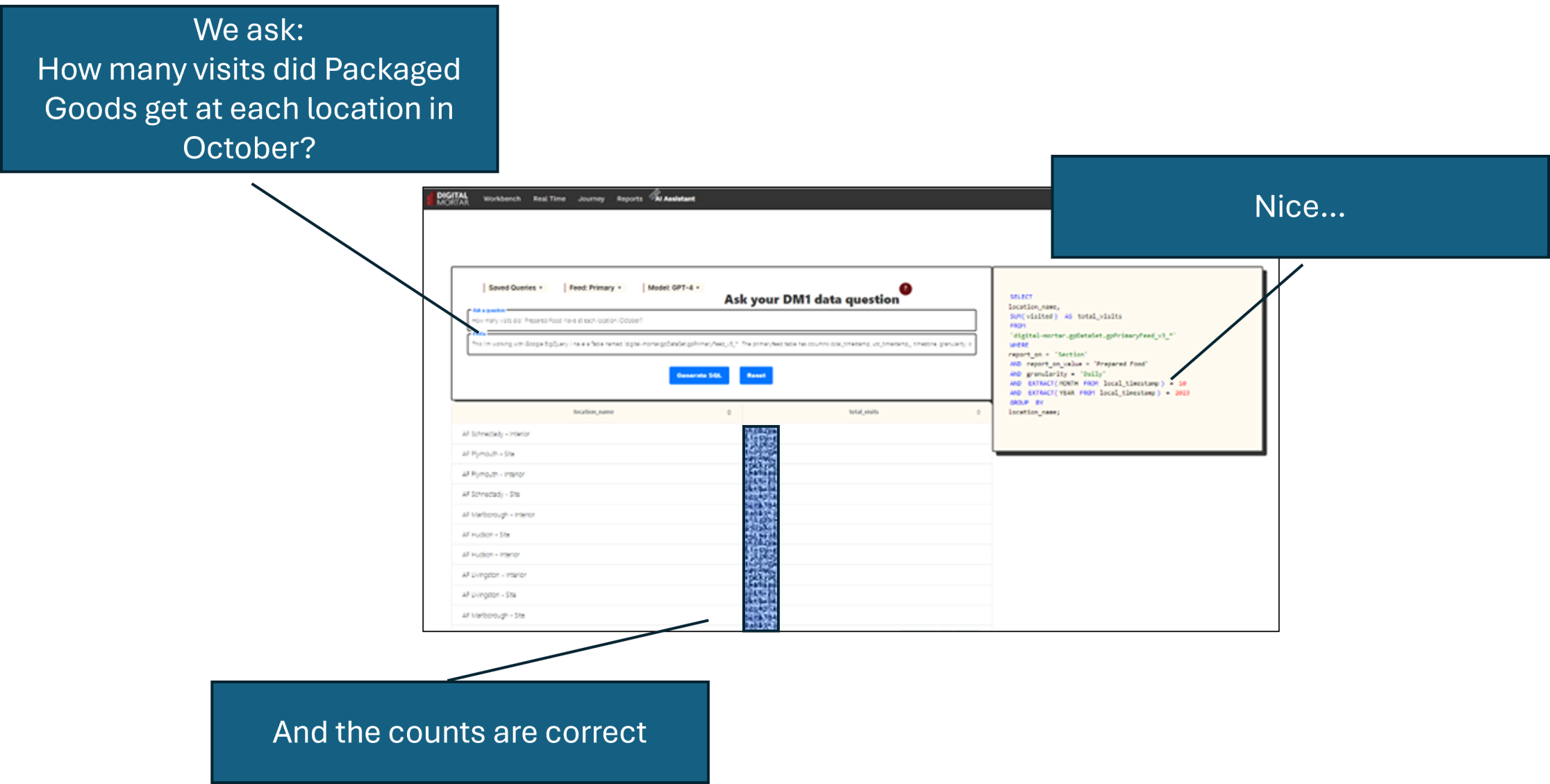
Just like magic.
Lessons:
#1. Tell ChatGPT about the quirks in your data
Treat ChatGPT like a new analyst and provide appropriate mentorship. It won’t explore your data the way a new analyst might (especially since the API requests don’t necessarily form a conversation), but it’s incredible at making connections (like Hudson to location_name). In this case, understanding a location’s dual representation in the database is critical knowledge for formulating queries correctly. This mentorship can’t be provided by the user because the whole point of the ChatGPT interface is that the user doesn’t know how to do this on their own, but once you’ve built it into the context, you’ve effectively leveraged your analysts’ expertise to the rest of your stakeholders. That’s what BI is all about.
#2: Tell ChatGPT about your key dimensions
An overwhelming number of user questions require ChatGPT to understand specific data values and which fields they are in. Our approach is to load all the values of low-cardinality fields into the Context. That takes care of things like getting the precise format of location names or understanding where “Dry Goods” lives in the database. If a key dimension has high-cardinality, cherry pick the rows that are most common. Even if a field has 1000 distinct values, 80% of the rows are often captured by the top 20 or so distinct values. Make sure ChatGPT knows about those.
#3: Tell ChatGPT how to limit queries
Summing all visits across time is rarely a useful exercise. But non-technical users nearly always suffer from a lack of specificity in their requests. This gives users bad answers, and it can also result in expensive or performance crippling SQL queries. Most non-SQL users can parse this SQL to understand what ChatGPT is doing:
AND EXTRACT(MONTH FROM local_timestamp) = 10 AND EXTRACT(YEAR FROM local_timestamp) = 2023
On the other hand, if the YEAR line isn’t there, most nonSQL users won’t realize they are getting data from every December.
#4: Give Samples
Samples really help ChatGPT do better. To paraphrase a classic line, a single sample may well be worth a thousand words.
#5: Except it’s not magic, it’s work
ChatGPT is amazing. And the work of transferring analyst knowledge to the context is easily justified. But if you don’t do the work, you won’t get good results, and the work of tuning never really stops. You need to continually monitor what users are asking and where ChatGPT is failing so that you can make the process better. In the end, our context includes customized instructions about our data common to all client, data from the client’s specific database to tell ChatGPT about what’s in key dimensions, and some specific instructions unique to each client (things like if a query is about pumps or EV Charging use the Site not Interior version of the data).
In my next post, I’ll explain how (and why) we integrated ChatGPT into our main platform interface when users are working with the data. Some of the same lessons apply – but we learned a whole bunch of new ones!