Machine Learning and Store Analytics
Machine Learning and Store Analytics
By Gary Angel
|April 25, 2018
Last week I spoke in Toronto at a Symposium focused on Machine Learning to describe what we’ve done and are trying to do with Machine Learning (ML) in our DM1 platform and with store analytics in general. Machine Learning is, in some respects, a fraught topic these days. When something is hard on the hype cycle, the tendency is to either believe it’s the answer to every problem or to dismiss the whole thing as an illusion. The first answer is never right. The second sometimes is. But ML isn’t an illusion – it’s a real capability with a fair number of appropriate applications. I want to cover – from our hands-on, practical perspective – where we’ve used ML, why we used ML and show a case-study of some of the results.
Just what is Machine Learning?
In its most parochial form, ML is really nothing more than a set of (fairly mature) statistical techniques dressed up in new clothes.
Here’s a wonderful extract from the class notes of a Stanford University expert on ML: (http://statweb.stanford.edu/~tibs/stat315a/glossary.pdf)
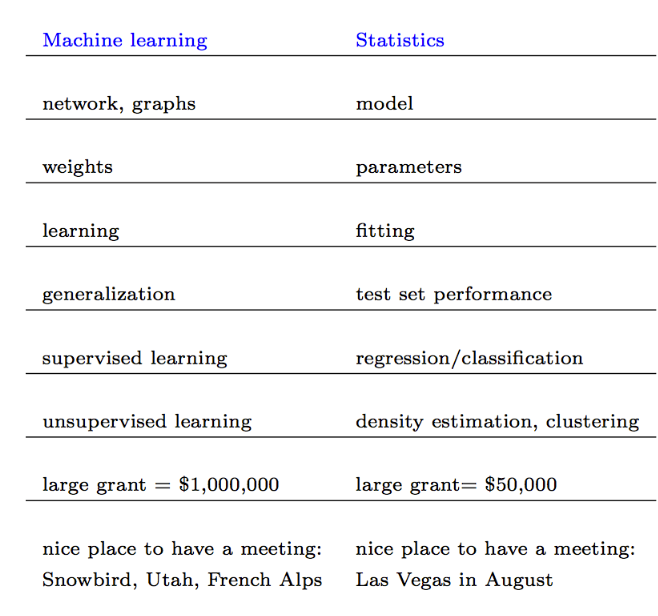
It’s pretty clear why we should all be talking ML not statistics! And seriously, wasn’t data science enough of a salary upgrade for statisticians without throwing ML into the hopper?
Unlike big data, I have no desire in this case to draw any profound definitional difference between ML and statistics. In my mind, I think of ML as being the domain of neural networks, deep learning and Support Vector Machines (SVMs). Statistics is the stuff we all know and love like regression and factor analysis and p values. That’s a largely ad hoc distinction (and it’s particularly thin on the unsupervised learning front), but I think it mostly captures what people are thinking when they talk about these two disciplines.
What Problems Have We Tried to Solve with ML
At a high-level, we’ve tackled three types of problems with ML (as I’ve casually defined it): improving data quality, shopper type classification, and optimal store path analysis.
Data quality is by far the least sexy of these applications, but it’s also the area where we’ve done the most work and where the everyday application of our platform takes actual advantage of some ML work.
When we setup a client instance on DM1, there’s a number of highly specific configurations that control how data gets processed. These configurations help guide the platform in key tasks like distinguishing Associate electronic devices from shopper devices. Why is this so important? Well, if you confuse Associates with shoppers, you’ll grossly over-count shoppers in the store. Equally bad, you’ll miss out on a real treasure trove of Associate data including when Associate/Shopper interactions occur, the ratio of Shoppers to Associates (STARs), and the length and outcome from interactions. That’s all very powerful.
If you identify store devices, it’s easy enough to signature them in software. But we wanted a system that would do the same work without having to formally identify store devices. Not only does this make it a lot easier to setup a store, it fixes a ton of compliance issues. You may tell Associates not to carry their own devices on the floor, but if you think that rule is universally followed your kidding yourself. So even if you BLE badge employees, you’re still likely picking up their personal phones as shopper devices. By adding behavioral identification of Associates, we make the data better and more accurate while minimizing (in most cases removing) operational impact.
We use a combination of rule-based logic and ML to classify Associate behavior on ALL incoming devices. It turns out that Associates behave quite differently in stores than shoppers. They spend more time. Go places shoppers can’t. Show up more often. Enter at different times. Exit at different times. They’re different. Some of those differences are easily captured in simple IF-then programming logic – but often the patterns are fairly complex. They’re different, but not so easily categorized. That’s where the ML kicks in.
We also work in a lot of electronically dense environments. So we not only need to identify Associates, we need to be able to pick-out static devices (like display computers, endless aisle tablets, etc.). That sounds easy, and in fact it is fairly easy. But it’s not quite as trivial as it sounds; given the vagaries of positioning tech, a static device is never quite static. We don’t get the same location every time – so we have to be able to distinguish between real movement and the type of small, Brownian motion we get from a static device.
Fixing data quality is never all that exciting, but in the world of shopper journey measurement it’s essential. Without real work to improve the data – work that ML happens to be appropriate for – the data isn’t good enough.
The second use we’ve found for machine learning is in shopper classification. We’re building a generalized shopper segmentation capability into the next release of DM1. The idea is pretty straightforward. For years, I’ve championed the notion of 2-tiered segmentation in digital analytics. That’s just a fancy name for adding a visit-type segmentation to an existing customer segmentation. And the exact same concept applies to stores.
As consultants, we typically built highly customized segmentation schemes. Since Digital Mortar is a platform company, that’s not a viable approach for us. Instead, what we’ve done is taken a set of fairly common in-store behavioral patterns and generalized their behavioral signatures. These patterns include things like “Clearance Shoppers”, “Right-Rail Shoppers”, “Single Product Focused Shoppers”, “Product Returners”, and “Multi-Product Browsers”. By mapping store elements to key behavior points, any store can then take advantage of this pre-existing ML-driven segmentation.

It’s pretty cool stuff and I’m excited to get it into the DM1 platform.
The last problem we’ve tackled with ML is finding optimal store paths. This one’s more complex – more complex than we’ve been comfortable taking on directly. We have a lot of experience in segmentation techniques – from cluster analysis to random forests to SVMs. We’re pretty comfortable with that problem set. But for optimal path analysis, we’ve been working with DXi. They’re an ML company with a digital heritage and a lot of experience working on event-level digital data. We’ve always said that a big part of what drew us to store journey measurement is how similar the data is to digital journey data and this was a chance to put that idea to the test. We’ve given them some of our data and had them work on some optimal path problems – essentially figuring out whether the store layout is as good as possible.
Why use a partner for this? I’ve written before about how I think Digital Mortar and the DM1 platform fit in a broader analytics technology stack for retail. DM1 provides a comprehensive measurement system for shopper tracking and highly bespoke reporting appropriate to store analytics. It’s not meant to be a general purpose analytics platform and it’s never going to have the capabilities of tools like Tableau or R or Watson. Those are super-powerful general-purpose analytics tools that cover a wide range of visualization, data exploration and analytic needs. Instead of trying to duplicate those solutions we’ve made it really easy (and free) to export the event level data you need to drive those tools from our platform data.
I don’t see DM1 becoming an ML platform. As analysts, we’ll continue to find uses for ML where we think it’s appropriate and embed those uses in the application. But trying to replicate dedicated ML tools in DM1 just doesn’t make a lot of sense to me.
In my next post, I’ll take a deeper dive into that DXi work, give a high-level view of the analytics process, and show some of the more interesting results.